Optimize Data Lakes with Amazon EMR, Redshift & Athena


8 min read

Table of contents
- Overview of Data Lake Integration
- Importance of AWS Tools
- Using Amazon EMR for Data Processing
- Best Practices for Amazon EMR
- Leveraging EMR for Machine Learning
- Utilizing Amazon Redshift in Data Lakes
- Amazon Athena for Data Lake Querying
- Comparing Amazon Redshift and Athena
- Getting the Most Out of Amazon EMR
- Supercharging Analytics with Amazon Redshift
- Harnessing the Power of Amazon Athena
- Why These Tools Matter in the Real World
- References
Are you ready to explore the fascinating world of data lakes?
Data Lake Integration with Amazon EMR, Redshift, and Athena is your ticket to mastering massive data management.
These powerful AWS tools make integrating data lakes a cinch. You'll gather, store, and analyze large datasets with ease and style.
Overview of Data Lake Integration
Ever wondered what magic a data lake in AWS can bring?
Unlike the traditional data warehouses, a data lake is a centralized hub. It's a place where you can keep all your structured and unstructured data, no matter the size.
From videos and images to social media feeds, data lakes add a touch of wonder to data collection.
AWS provides a data lake solution that integrates smoothly with Amazon EMR, Redshift, and Athena.
These integrations allow you to process and analyze data easily. They transform raw data into meaningful insights with minimal effort.
Importance of AWS Tools
Amazon Redshift is like the muscle behind your data analytics. It enables quick and powerful analysis of huge amounts of data.
While Redshift itself isn’t a data lake, it complements them. It offers fast analytics and improved performance.
Supported by an AWS data pipeline setup, these tools ensure smooth data flow. They enable businesses to take full advantage of vast data resources.
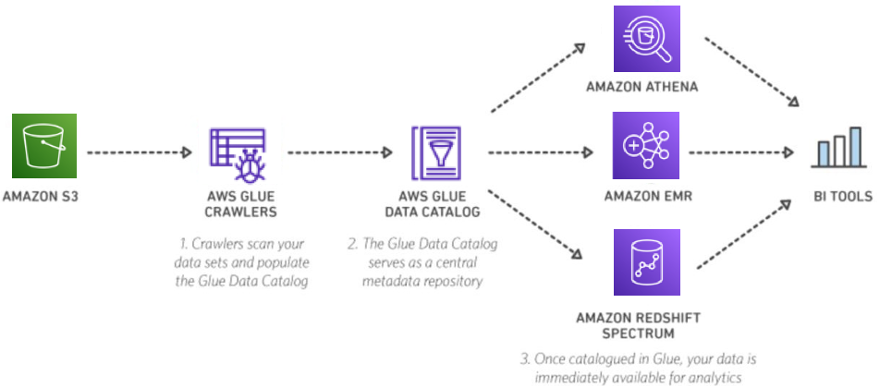
Embracing the power of Amazon EMR is like turbocharging how you manage data lakes.
With its robust features, Amazon EMR is a standout solution for large-scale data processing.
But why exactly? Let’s explore how it works and why it's essential for modern data management.
Using Amazon EMR for Data Processing
Amazon EMR simplifies big data tasks like a pro. Picture managing petabytes of data effortlessly—Amazon EMR makes that a reality.
One major benefit is its magical ability to process data, especially with Apache Spark. You might be asking, "How do you use Amazon EMR with data lakes?" It's quite straightforward.
Configure clusters to match your data requirements. Each EMR cluster can handle data, perform ETL tasks, and execute complex algorithms.
This allows for seamless data processing and easy scaling. When you hear about Amazon EMR data lake solutions, imagine a system that processes vast amounts of data smoothly and efficiently.
Curious about the differences between AWS Athena and EMR? Both are designed to query S3 using standard SQL and store results.
Athena saves results on S3, which can be easily moved to Redshift. In contrast, Spectrum operates directly from Redshift.
This versatility makes Amazon EMR a game-changer.
Best Practices for Amazon EMR
Getting the most from Amazon EMR goes beyond setup. Implementing best practices ensures maximum benefits.
Did you know integrating data lakes with Amazon EMR can make data processing cost-effective? You can adjust instances to balance performance and cost.
It’s about understanding workload patterns and using Amazon EC2 spot instances to cut costs.
As a personal takeaway, I led a project where switching to EMR reduced our processing costs by 40%!
Tech enthusiasts often wonder if Athena federated queries are superior to Redshift. It depends on specific scenarios.
For straightforward access to S3 data, Athena is great. But for complex analysis involving multiple datasets, Redshift might suit you better.
Leveraging EMR for Machine Learning
Integrating machine learning into your data lakes with Amazon EMR is incredibly exciting. Imagine running ML models that analyze and predict trends on terabytes of data—all within the EMR framework.
This is not just about crunching numbers; it's about turning insights into actionable strategies. Using EMR for machine learning enables real-time predictive analytics, transforming decision-making processes.
As a data fan, there’s nothing quite like watching models train at lightning speed with EMR's resources.
Using Amazon EMR not only equips you with efficient data processing tools but also opens innovative paths in analytics and machine learning.
This ensures your data lakes become powerful engines for insight and business transformation.
Jumping into the world of big data, integrating data lakes with tools like Amazon Redshift and Athena is revolutionary.
From my experience, these tools transform raw data into valuable insights, efficiently and scalable.
Utilizing Amazon Redshift in Data Lakes
When discussing Redshift and data lake integration, we're engaging with something significant.
Redshift simplifies scaling data lakes and offers robust analytics. Imagine managing vast data across clusters with real-time insights. It feels like having a highly skilled number-crunching personal assistant!
Many wonder, "What is Amazon Redshift ODBC?" Simply, it connects applications to Redshift, enabling seamless data flow and transformation.
Renowned for its OLAP abilities, Redshift delivers outstanding performance in complex query processing.
In the data landscape, Redshift isn't just good for OLAP—it's custom-made for it.
Amazon Athena for Data Lake Querying
Switching gears, let's explore using Athena for data lake querying. Athena is a serverless wonder.
You can run SQL queries on massive data stored in Amazon S3 without setting up any infrastructure. It's like magic! Just point, click, and query.
This flexibility lets you analyze diverse data types—from structured to semi-structured—transforming insight-gathering methods.
People often ask, "Can Amazon Athena connect to Redshift?" Yes, it can! Through federated queries, both combine for more detailed data analysis.
Optimizing data lake queries in Redshift and boosting them with Athena enhances data access and speed.
Comparing Amazon Redshift and Athena
The debate often arises: Amazon Athena vs. Redshift for data lakes—who’s the hero? It depends on your goals. Redshift is strong for high-performance analytics on structured data.
Athena, on the other hand, offers ease by querying data directly from the lake using standard SQL.
What’s the difference? While both excel in analysis, Redshift shines in OLAP with structured data.
Conversely, Athena thrives with its serverless architecture for direct querying.
Why use Redshift instead of Athena? If advanced OLAP and a dedicated data warehouse are your needs, choose Redshift. For quick, flexible queries without server management, go with Athena.
In summary, combining Redshift's scalability with Athena's query ease creates a strong toolset for any data-driven business.
As we delve deeper into data lakes, these tools will transform our data architectures.
Optimizing and Maximizing Performance
Navigating the vast seas of data stored in Amazon S3 data lakes is both an art and a science.
By using tools like Amazon EMR, Redshift, and Athena, we can make this process smoother. What's the secret sauce, you ask? Let’s break it down.
Optimization Strategies
First, let’s talk about optimizing your Amazon S3 data lake. It's all about refining your Athena queries for the best performance.
The great thing is, Athena connects to S3 effortlessly! It supports a variety of data formats, making it super flexible.
You can use partitioning and efficient formats like Parquet. This boosts your query speeds big time. Imagine cutting storage costs and query times, all at once!

Future Trends and Developments
Now, what about Amazon EMR and making your data lake more efficient? As trends evolve, the focus is shifting toward Amazon Redshift's serverless data lake capabilities.
The debate often arises around Redshift serverless. It’s simple: you pay per query. This method is perfect for those varying workloads.
In contrast, Redshift’s traditional model may rack up costs even when usage is low. So, deciding where to invest depends on your workload patterns.
These might start to lean more toward serverless as trends change.
Final Thoughts on AWS Integration
When it comes to AWS integration, a key question pops up: do we need data lakes and warehouses? Absolutely, yes.
They aren’t replacements, but partners that enhance data processing. Data lakes serve as the staging and processing layers. They work great with data warehouses, forming a solid infrastructure.
Plus, integrating these services can be incredibly cost-effective, maximizing your AWS investments.
Getting the Most Out of Amazon EMR
Amazon EMR (Elastic MapReduce) is amazing for handling large data volumes. It's perfect for big data tasks using Hadoop or Spark.
The best part? It’s incredibly affordable as you scale up or down. AWS lets you pay only for what you use, so no more worries over hardware costs.
I remember a project where our data seemed overwhelming.
Switching to Amazon EMR was a game-changer. We could parallelize tasks and handle what seemed impossible.
This showed me the power of cloud-based solutions.
Supercharging Analytics with Amazon Redshift
For fast data warehousing and analytics, Amazon Redshift is unbeatable.
Did you know it can analyze exabytes of data? That's a lot! Redshift excels with its scaling abilities and fits right into your data setup.
Its columnar storage boosts performance with better data compression.
Plus, Amazon claims you can cut costs by over 75% with their pricing model compared to traditional ways.
I was blown away when Redshift tackled complex queries quickly.
Our past databases couldn’t compare. Imagine slicing down analysis time and gaining rapid insights — it felt like magic!
Harnessing the Power of Amazon Athena
Amazon Athena offers instant query abilities. It’s serverless, so there's no infrastructure to worry about.
You only pay per query, which is budget-friendly for many.
Remember waiting forever for SQL queries? Athena changed that for me with lightning-fast results. It was pivotal in speeding up our data-driven decisions.
Why These Tools Matter in the Real World
The trio of Amazon EMR, Redshift, and Athena can transform chaotic data lakes into streamlined sources of insights.
They cater to modern business demands, helping you navigate through vast data with ease.
Want to know more about these tools? Check out our detailed comparison of AWS data lake tools.
If you’re aiming to boost your data lake skills, combining these tools can be powerful. Get ready to upgrade your data strategies with Amazon’s robust suite.